Word Count Tool
In Google Docs, the word count tool looks like this:
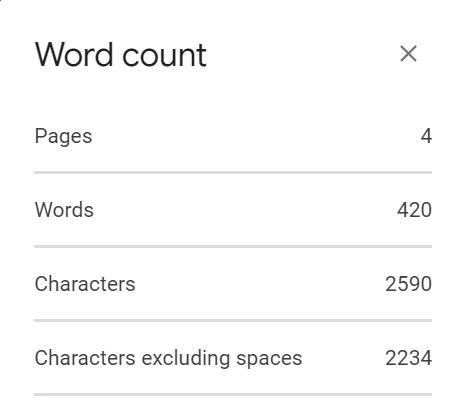
Pages would not make sense, but your goal is to implement every other count.
Definitions
Words are strings of text separated by any amount of whitespace (spaces, tabs, newlines). Characters are all printable bytes*. For the sake of this challenge, you may assume all inputs will consist of printable bytes. Note that Google Docs does not count newlines in its character count, so you must do the same.
*I define printable bytes as the variable string.printable in Python, which is shown below.
>>> string.printable
'0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~ \t\n\r\x0b\x0c'
Input
A string of text, or a list of strings instead of a multiline string if you wish.
Output
The 3 counts (words, characters, characters without spaces) in any order, and in an array if you like.
Examples
Input -> [words, characters, characters without spaces]
"Hello world" -> [2, 11, 10]
"H3ll0 w0r1d" -> [2, 12, 10]
"Hello \t\nworld" -> [2, 12, 11]
"\n\n\n" -> [0, 0, 0]
" " -> [0, 3, 0]
This is code golf, so shortest code wins.
[Ruby], 55 bytes -> …
4y ago
[APL (Dyalog Unicode)], 27 byt …
4y ago
Japt v2.0a0, 19 18 17 bytes …
4y ago
[Python 3.8], 73 bytes …
3y ago
[Wolfram Language (Mathematica …
3y ago
JavaScript (Node.js), 60 bytes …
3y ago
Lua 5.4, 62 bytes ``` lua …
3y ago
Ruby, 48 bytes ```ruby ->a …
3y ago
[Haskell], 47 bytes …
3y ago
9 answers
You are accessing this answer with a direct link, so it's being shown above all other answers regardless of its score. You can return to the normal view.
Lua 5.4, 62 bytes
_,w=s:gsub('%w+',0)_,c=s:gsub('[^\n]',0)_,n=s:gsub('[%g\t]',0)
Another version, 65 bytes:
p={'%w+','[^\n]','[%g\t]'}for i=1,#p do _,r[i]=s:gsub(p[i],'')end
0 comment threads
Ruby, 55 bytes
->a{[a.split,a.tr($/,''),a.gsub(/[
]/,'')].map &:size}
split removes all whitespace, but lines doesn't for some reason. Would've been useful in place of the tr.
0 comment threads
APL (Dyalog Unicode), 27 bytes
Anonymous tacit prefix function
'\w+' '.' '[^ ]'{≢⍺⎕S⍬⊢⍵}¨⊂
'\w+' '.' '[^ ]'{…}¨⊂ apply the following anonymous lambda on each of the PCRE patterns (⍺) and the entire string (⍵):
⊢⍵ on the string
⍺⎕S⍬ find matches for the pattern
≢ tally (count) them
Japt v2.0a0, 19 18 17 bytes
I need more caffeine!
Takes input as an array of lines. Output is a reversed array.
[Uc¸¬U¬Ucq\s f]ml
Try it - includes all test cases, header splits string on newlines for ease of input. footer reverse the output for easier verification.
[Uc¸¬U¬Ucq\s f]ml :Implicit input of array U
[ :Construct an array containing
Uc :1. Map U then flatten
¸ : Join with spaces
¬ : Join
U¬ :2. Join U
Uc :3. Map U then flatten
q : Split on
\s : Regex /\s/g
f : Filter, to remove empty strings
] :End array
m :Map
l : Length0 comment threads
Wolfram Language (Mathematica), 70 bytes
{Tr[1^StringSplit@#],StringLength@#,StringLength@StringDelete[#," "]}&
What made me decide to use Mathematica for string processing? I don't know. But at least it has the required builtins.
0 comment threads
Python 3.8, 73 bytes
lambda x:[len(x.split()),len(x.replace('\n','')),len(''.join(x.split()))]
0 comment threads
JavaScript (Node.js), 60 bytes
s=>[/\w+/g,/./g,/[\S\t]/g].map(p=>(v=s.match(p))?v.length:0)
0 comment threads

1 comment thread